
Entity SEO: vom Keyword zur Entität

Google startete 2012 ihren Knowledge Graph unter der Devise “Things, not Strings”, damit bemerkend, dass es sich in der Datenbank eher um Dinge und weniger um Zeichenketten drehe. Der Knowledge Graph begann initial mit 500 Millionen dieser Objekte sowie mehr als 3,5 Milliarden Fakten und Beziehungen zwischen den verschiedenen Objekten. Seitdem durchsucht Google das Web nicht mehr nur nach Seiten und Links, sondern sammelt Daten und extrahiert Entitäten.
Eine Entität beschreibt dabei ein reales weltliches Objekt wie einen Menschen, einen Ort oder andere Dinge. Aber auch abstrakte Themen und Konzepte wie z.B. Marken oder Religionen können durch Entitäten ausgedrückt werden. Die Eigenschaften dieser Entitäten werden durch ihre Beziehungen, die sie miteinander verbinden, festgelegt. Google selbst bezeichnet Entitäten als “Nodes”, ihre Beziehungen untereinander werden “Edges” genannt.
Googles Knowledge Graph ist also eigentlich ein Entitäten-Graph, wobei die Knowledge Panels deren visuelle Darstellung in den Suchergebnissen repräsentieren. Für den Suchmaschinengiganten sind Entitäten eine Sache oder ein Konzept, welches
- einzigartig,
- eindeutig,
- klar definiert und
- unterscheidbar
ist.
Der Vorteil: Entitäten sind sprachunabhängig. Dadurch ist die entitätsbasierte Suche effizienter, da die Suchmaschine die Inhalte aller Sprachen gleichzeitig abfragen kann, um die besten Informationen zu finden.
Mit der Geburt des Knowledge Graph war die Websuche nach Sehenswürdigkeiten, Prominenten, Städten, Sportteams, Gebäuden, geografischen Merkmalen, Filmen, Himmelsobjekten, Kunstwerken und viel mehr nicht mehr dieselbe. Der erste Schritt zum “Entity-First Indexing” war gemacht.
Auf dem Weg zur Entitäten-Optimierung
Seit diesem Tag ist Google auf der Suche nach zusätzlichen Quellen, die aktuelle und zuverlässige Informationen über Entitäten abseits der herkömmlichen Wissensdatenbanken liefern. Die Suchmaschine erfuhr bisher nur etwas über Entitäten, indem es Informationen aus Tabellen und Spalten-getrennten Listen aus Wikipedia, IMDB und Co. extrahierte. 2010 kaufte Google die Firma Metaweb, welches die Open-Content-Datenbank Freebase betrieb. Freebase wurde im Jahr 2015 zugunsten der freien Datenbank Wikidata geschlossen.
Das Hummingbird Update im Jahr 2013 war ein weiterer Schritt Googles im Wandel zur Antwortmaschine. Hier wurde noch mehr Fokus auf die jeweilige Nutzerintention hinter der Suchanfrage gelegt als auf die Suchbegriffe selbst. Das gilt vor allem bei zusammengesetzten Suchanfragen (sogenannten compositional queries), z. B. “wie heißt der trainer von schalke 04”. Derartige Suchanfragen bestehen aus einer ersten Entität, einer zweiten Entität und ihrer Beziehung miteinander. Eine Entitäten-basierte Suche kann in solchen Fällen bessere Suchergebnisse bieten als eine Keyword-basierte.

Wie geht Google mit Entitäten um?
Google nutzt zur Identifizierung von Entitäten sogenante MREIDs (Machine-Readable Entity IDs) , also eindeutige und maschinenauslesbare Identifikationsnummern. Diese werden übergreifend auf vielen eigenen Services (wie z.B. Google Trends, Google Maps, Google Lens oder der Google Reverse Image Search) verwendet. Es gibt historisch gewachsen 2 Arten dieser IDs:
- Freebase MREIDs für Entitäten, die erstellt wurden, während Freebase noch online war. Sie verwenden das Format /m/[a-z0–9]+.
- Neue MREIDs für Entitäten, die nach der Beendigung von Freebase erstellt wurden. Sie verwenden das Format /g/[a-z0–9]+.
Was ist aber, wenn zu einer Suchanfrage mehrere Entitäten in Frage kommen, der User z. B. wissen möchte, wer denn nun wirklich der beste Fußballer der Welt ist (https://www.google.de/search?q=beste+fussballer)? Ein derartiges Ranking von Entitäten erfolgt dann anhand von 4 Faktoren:
- Beziehung: hierbei zählt ein häufiges gemeinsames Auftreten (die sogenannte Co-Occurrence) auf Websites bestimmter Autorität, z. B. “Angela Merkel” und “Bundeskanzlerin”
- Prominenz: diese meint die Wichtigkeit einer Entität global und in ihrer Domäne, z. B. hat “Rand Fishkin” in der Domäne “SEO” einen (leider) höheren Wert als “Florian Elbers”
- Beitrag: hier wird der Beitrag einer Entität zu einer Kategorie festgelegt, indem dieser durch externe Signale (Bewertungen, Ranglisten, etc.) bestimmt wird, z. B. Reviews des eigenen Produktes auf anderen Websites
- Preis: bestimmt den Wert einer Entität innerhalb ihrer Kategorie durch Auszeichnungen und Preise, z. B. Filme, die einen oder mehrere Academy Awards (Oscars) oder Golden Globes gewonnen haben
Wie optimiert man die eigenen Inhalte auf Entitäten?
Ziel der Suchmaschinenoptimierung für Entitäten, dem Entity SEO, ist das Stärken der Verbindung unserer Website oder Marke mit bestimmten Begriffen und Entitäten. Hierfür gibt es mehrere Ansätze, wobei wir uns letzterem hier intensiver widmen werden:
- Content: Content ist King, klar. Aber in diesem Fall ist der Kontext Kaiser. Um die eigenen holistischen Inhalte weiter zu optimieren, sollte man diejenigen Keywords, für die man ranken möchte googlen und sich dann die Inhalte der Top 10 Ergebnisse genauer anschauen. Diejenigen Entitäten, die in deren Content referenziert werden, sind auch Kandidaten für den eigenen Inhalt.
- Linkbuilding: bisher galten Links als Ausdruck der Wichtigkeit und Popularität von Inhalten. Heute sind sie Ausdruck des Zusammenhangs zwischen Entitäten. Dies gilt sowohl für Links als auch für Mentions, also nicht verlinkte Erwähnungen auf externen Websites. Ziel ist es hier, Verlinkungen von Seiten zu bekommen, die eine starke Beziehung zu der eigenen Entität haben.
- Semantische Daten: diese auch als strukturiert bezeichnete Daten bieten die Möglichkeit, zuvor unklassifizierte Informationen als Entitäten auszuzeichnen. Über “SameAs” lässt sich im Quelltext die URL einer Referenz-Webseite an die Suchmaschine übermitteln, welche die Identität des Elements eindeutig angibt. Dadurch wird die Entität, die durch zwei Ressourcen, also URLs, repräsentiert wird, als ein und dieselbe Sache betrachtet.
Entity SEO über “SameAs”
Die Methode strukturierte Daten hierfür zu nutzen ist gar nicht mal neu. 2014 wies der SEO-Blog “Search Engine Land” in einem Post darauf hin, dass Websites anhand von SameAs angeben können; von welchen “Entitäten” sie in ihrem Content sprechen und Suchmaschinen damit vermitteln können, dass diese Entitäten die “selben wie” auf anderen Websites oder Entitäts-Datenbanken sind. 
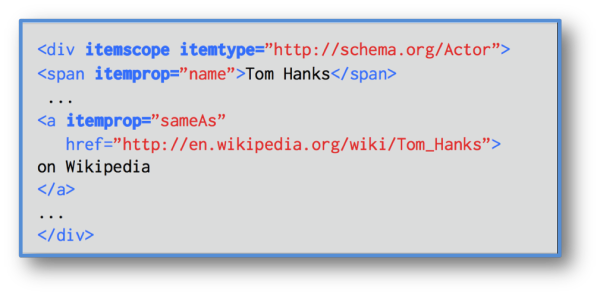
Die einzige Änderung bei der heutigen Entitäten-Optimierung ist jedoch die, dass wir anstatt einer Wikipedia-Seite wie im obigen Beispiel, direkt die URL eines Panels des Google Knowledge Graph angeben. Dazu nutzen wir die direkte Datenbankanbindung “Google Knowledge Graph Search API”. Nachdem man sich hierfür kostenlos anmeldet hat, kann man mit dem eigenen API-Schlüssel Abfragen an Google senden und bekommt dann z. B. heraus, dass die US-Sängerin Taylor Swift die MREID /m/0dl567 besitzt (wie man an diese ID auch über Google Trends, Wikidata oder das passende Knowledge Panel selbst kommt, erklärt der Blogartikel „Leveraging Machine-Readable Enitiy IDs for SEO„). Wir können nun über die von Google bevorzugte Auszeichnung von struktierten Daten, JSON-LD, im Quelltext unseres Contents hinterlegen, dass es sich auf unserer URL um Taylor Swift dreht:
„sameAs“ : [ „https://www.google.com/search?q=Taylor+Swift&kponly&kgmid=/m/0dl567“ ]
Zur generellen Einbindung von JSON-LD gibt es von Google eine Anleitung.
Die eigene Entität anlegen
Falls eine Entität, die man auszeichnen möchte (z. B. das eigene Unternehmen oder die eigene Person) noch nicht in Googles Knowledge Graph vorhanden ist, kann man diesen manuell füttern. Dazu legt man auf wikidata.org einen kostenlosen Account an und erstellt das gewünschte “Item” (so heißen Entitäten bei Wikidata). Der Vorteil von Wikidata: hier werden Informationen zur einer Entität in allen Sprachen in einer Ressource vereint.
Am besten sucht man sich vorher einen ähnlichen Eintrag in der Datenbank und baut diesen mit den eigenen Daten nach.
Aber Vorsicht: Wie bei allem Wikis kann das Anlegen einer Entität auch schiefgehen. Um Spamming zu vermeiden, hat Wikidata Kriterien aufgestellt. Die Fehlermeldung “Doesn’t meet the notability criteria. No sitelinks, internal links, external IDs or references” nach dem Erstellen des “Items” informiert darüber, dass diese Kriterien nicht erfüllt wurden. Hier muss man dann nachbessern. Falls z.B. der Eintrag der eigenen Person angenommen wurde und die Suche bei Google nach dem eigenen Namen ein Knowledge Panel anzeigt, kann man dies für sich beanspruchen.
Hier findest du eine Anleitung zur Bestätigung der eigenen Identität auf Google. Hier kann schnell und einfach verifiziert werden, dass man z.B. autorisierter Vertreter einer Organisation ist.
Was bringt mir das?
Im jetzigen Moment ist der Effekt solch einer Optimierung von und für Entitäten noch nicht wirklich bestätigt. Das Ziel, die beste Antwort bzw. das bestmögliche Erlebnis für den Suchmaschinen-Benutzer zu generieren, ist jedoch nicht erst seit den letzten Core-Algorithmus-Update von Google, bei denen Expertenwissen, Autorität & Vertrauenswürdigkeit relevante Faktoren waren, immer wichtiger geworden. Der hier beschriebe Weg über Entity-SEO bietet hierfür einen weiteren Ansatz, einen maschinenauslesbaren Weg, Suchmaschinen und Nutzern gleichermaßen zeigen können, dass die eigenen Inhalte kompetent, verlässlich und vertrauenswürdig sind.
Author