Wie mache ich eine Crawl Budget-Optimierung?


- Was ist das Crawl Budget?
- Wie groß ist mein Crawl Budget?
- Was ist der Unterschied zwischen Crawl Budget und Crawl Demand?
- Was passiert, wenn das Crawl Budget nicht ausreicht?
- Für wen ist das Crawl Budget relevant?
- Wie kann ich herausfinden, was gecrawlt wird?
- Wie kann man das Crawl Budget optimieren?
- 7 Maßnahmen zur Crawl Budget Optimierung
- Deine Checkliste für die Crawl Budget Optimierung
Die Crawl Budget-Optimierung gehört zum technischen SEO und befasst sich mit dem effektiven Crawling der eigenen Website durch Suchmaschinen-Bots. Ziel ist es, dass möglichst alle Neuerungen und Änderungen der Website schnell in den Suchmaschinenindex (SERPs) aufgenommen werden und im zweiten Schritt gute bzw. bessere Rankings erreichen. Die Crawl Budget-Optimierung ist besonders für große Websites mit vielen Unterseiten relevant, wie beispielsweise Online-Shops.
![]()
![]() Die Optimierung des Crawl Budgets ist kein Rankingfaktor und führt nicht zu besseren Rankings. Aber es ist eine Maßnahme, neue und aktualisierte Inhalte schneller in den Index zu bekommen — und damit ggf. schneller bessere Rankings zu erreichen.
Die Optimierung des Crawl Budgets ist kein Rankingfaktor und führt nicht zu besseren Rankings. Aber es ist eine Maßnahme, neue und aktualisierte Inhalte schneller in den Index zu bekommen — und damit ggf. schneller bessere Rankings zu erreichen.
Was ist das Crawl Budget?
 Damit die Suchmaschinen mit dem Crawling der aber-millionen Websites dieser Welt klar kommen, wird der Umfang der täglichen Crawls für jede Website limitiert — es wird also nicht täglich die gesamte Website gecrawlt, sondern nur ein bestimmter Teil davon. Das bedeutet: für jede Website wird ein tägliches Budget für das Crawling festgelegt. Das ist in der Regel eine Zeiteinheit X, die die Crawler deiner Website widmen. Dabei wird alles erfasst, was innerhalb dieses Zeitraumes gecrawlt werden kann.
Damit die Suchmaschinen mit dem Crawling der aber-millionen Websites dieser Welt klar kommen, wird der Umfang der täglichen Crawls für jede Website limitiert — es wird also nicht täglich die gesamte Website gecrawlt, sondern nur ein bestimmter Teil davon. Das bedeutet: für jede Website wird ein tägliches Budget für das Crawling festgelegt. Das ist in der Regel eine Zeiteinheit X, die die Crawler deiner Website widmen. Dabei wird alles erfasst, was innerhalb dieses Zeitraumes gecrawlt werden kann.
Wie groß der Umfang ist, wird von den Suchmaschinen selbst festgelegt und kann durch Webmaster oder SEOs nicht beeinflusst werden. Allerdings passen die Suchmaschinen das Crawl Budget daran an, wie häufig durchschnittlich neue Inhalte dazu kommen oder aktualisiert werden. Eine Website, die viele neue Inhalte erstellt oder aktualisiert, wird ein höheres Crawl Budget erhalten, als eine Website, an der sich kaum etwas tut.
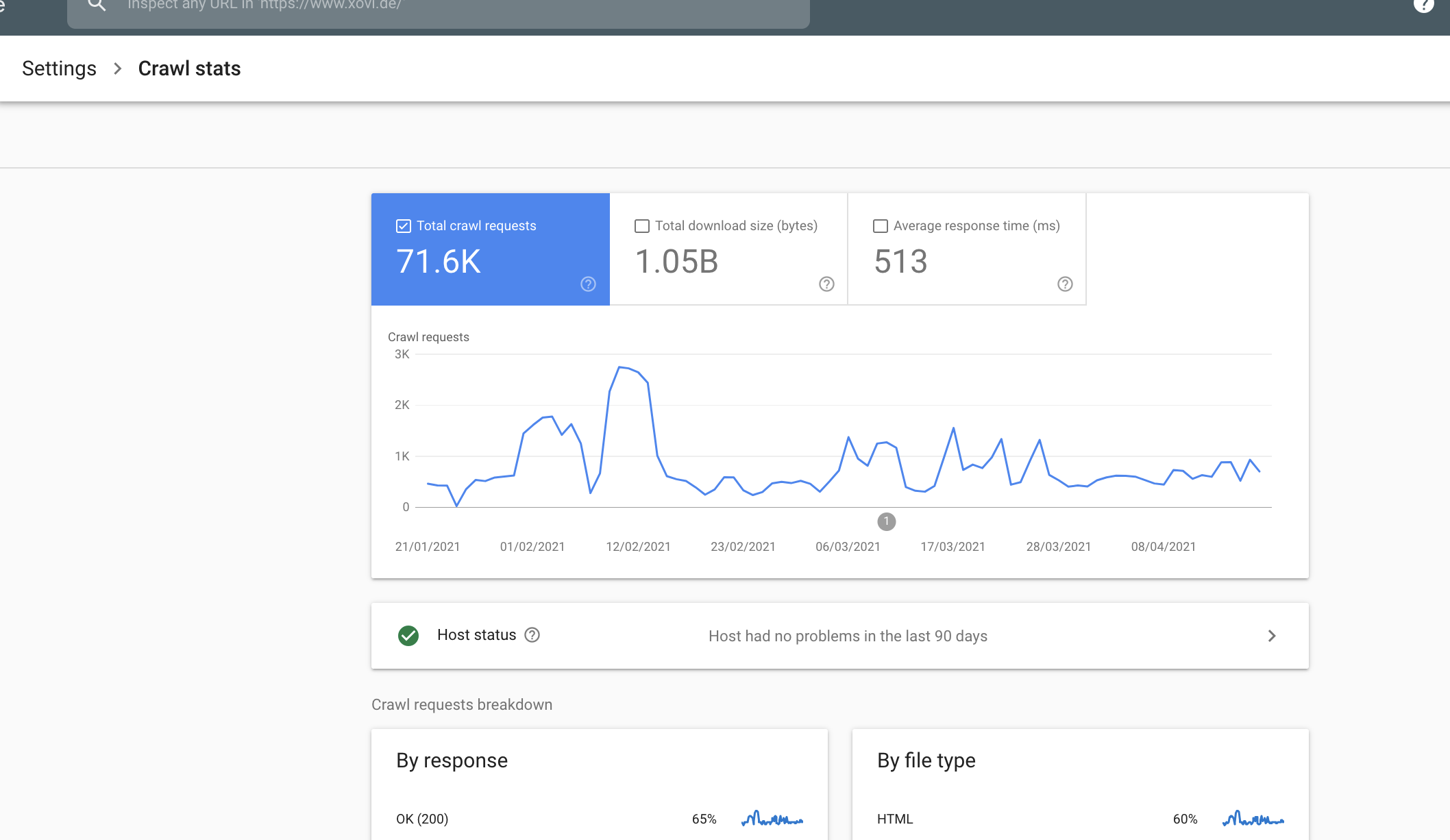
Wie groß ist mein Crawl Budget?
Du kannst das Crawl Budget deiner Website in der Google Search Console einsehen. Du findest es unter Settings – Crawl Stats.
Was ist der Unterschied zwischen Crawl Budget und Crawl Demand?
Das Crawl Budget ist der Umfang der Crawls, die die Suchmaschine deiner Website zuweist.
Der Crawl Demand ist die Menge an Crawls, die benötigt würde, um alle Änderungen deiner Website zu erfassen. In einigen Fällen kann es vorkommen, dass der Crawl Demand deutlich über dem Crawl Budget liegt.
Das ist zum Beispiel bei einem Relaunch der Fall. Dann stellt die Suchmaschine fest, dass für die Aktualisierung aller Seiten mit Veränderungen plötzlich deutlich mehr Crawls benötigt werden, als normalerweise im Crawl Budget vorgesehen. Um die Änderungen schnell zu erfassen, wird das Crawl Budget dann vorübergehend erhöht. Ist der Crawl Demand dann wieder gesunken, sinkt auch das Crawl Budget wieder.
Was passiert, wenn das Crawl Budget nicht ausreicht?
Wie bereits erwähnt, bezieht sich das Crawl Budget auf die dem Umfang der täglichen Crawls deiner Website. Überschreitet die Anzahl der Unterseiten mit Veränderungen regelmäßig das Crawl Budget, werden diese Inhalte an den darauffolgenden Crawl-Tagen erfasst.
Ein Beispiel: Angenommen, dein Crawl Budget umfasst täglich etwa 1000 Seiten, deine Website besteht aber aus ca. 10.000 URLs. Neue und aktualisierte Inhalte kommen dann nicht am selben Tag in den Index, sondern ggf. mit einigen Tagen Verzögerung.
Das kann besonders dann der Fall sein, wenn die neuen oder aktualisierten Inhalte auf Unterseiten sind, die nicht zu den wichtigen Seiten in deiner Website-Struktur zählen. Grundsätzlich ist davon auszugehen, dass die strukturell wichtigen Seiten deiner Website häufiger gecrawlt werden, als Unterseiten mit einer großen Klicktiefe.
![]()
![]() Das Crawling ist kein Rankingfaktor und hat keinen Einfluss auf deine Rankings. Reicht dein Crawl Budget nicht aus, bedeutet das lediglich, dass Änderungen oder neue Inhalte zeitverzögert in den Index aufgenommen werden. Das kann im schlimmsten Fall zu verpassten Traffic- und Umsatzsteigerungen führen, wenn die Seite erst später (re-)evaluiert und (besser) positioniert wird. Welche Rankings deine Inhalte erhalten, wird allerdings nicht beeinflusst.
Das Crawling ist kein Rankingfaktor und hat keinen Einfluss auf deine Rankings. Reicht dein Crawl Budget nicht aus, bedeutet das lediglich, dass Änderungen oder neue Inhalte zeitverzögert in den Index aufgenommen werden. Das kann im schlimmsten Fall zu verpassten Traffic- und Umsatzsteigerungen führen, wenn die Seite erst später (re-)evaluiert und (besser) positioniert wird. Welche Rankings deine Inhalte erhalten, wird allerdings nicht beeinflusst.
![]()
![]() Einzelne Seiten, die schnell gecrawlt werden sollen (z.B. aktualisierte Artikel), kannst du mit dem URL Prüftool der Google Search Console für einen gesonderten Crawl anmelden. Dann musst du nicht auf darauf warten, dass diese Unterseite eventuell erst in einigen Tagen gecrawlt wird.
Einzelne Seiten, die schnell gecrawlt werden sollen (z.B. aktualisierte Artikel), kannst du mit dem URL Prüftool der Google Search Console für einen gesonderten Crawl anmelden. Dann musst du nicht auf darauf warten, dass diese Unterseite eventuell erst in einigen Tagen gecrawlt wird.
Für wen ist das Crawl Budget relevant?
Das Crawl Budget wird schnell für große Websites knapp, auf denen sich täglich viele Änderungen ergeben oder die eine große Anzahl an Unterseiten haben, die eigentlich nicht gecrawlt werden müssten. Besonders häufig betroffen sind Online-Shops mit tausenden Produkten, zahlreichen Produktkategorien, Wunschlisten, Empfehlungslisten, Filtermöglichkeiten, Suchfunktionen, und, und, und.
Wenn du bemerkst, dass neue Seiten oder aktualisierte Inhalte sehr lange brauchen, bis sie in den index aufgenommen werden, ist ein Blick auf dein Crawl Budget sinnvoll.
Wie kann ich herausfinden, was gecrawlt wird?
Ganz einfach: Indem du deine Website selbst crawlen lässt und dir die Ergebnisse genau anschaust. Dafür kannst du beispielsweise die Crawl Analyse von Screaming Frog benutzen.

Die Ergebnisse werden analysiert und mit deiner XML Sitemap abgeglichen. Im Idealfall sind beide nahezu identisch. Meistens stellt sich jedoch heraus, dass viele Seite unnötig gecrawlt werden. Diese Seiten kannst du mit der Crawl Analyse identifizieren.
Achte beim Durchführen der Crawl Analyse darauf, dass du die Seite so crawlst, wie der Googlebot es tun würde. Nimm dazu folgende Einstellungen vor:
- JavaScript-Rendering aktivieren
- ‘respect noindex’ aktivieren
- ‘respect canonical’ aktivieren
- ‘respect robots.txt’ aktivieren
- XML-Sitemap crawlen
Beim URL-Rewriting übernimmst du alle Parameter so, wie sie auch in der Google Search Console angelegt sind. Als irrelevant markierte Parameter müssen also auch bei der Crawl Analyse mit Screaming Frog entsprechend angegeben werden.
Disallow statt noindex
Überprüfe vor allem, welche und wie viele Seiten mit dem noindex-Tag ausgezeichnet wurden. Handelt es sich um hunderte oder tausende Seiten, solltest du sie (sofern möglich) stattdessen über die robots.txt per disallow vom Crawling ausschließen.
Wie kann man das Crawl Budget optimieren?
Der Begriff der Crawl Budget-Optimierung bezieht sich nicht auf eine Veränderung des Crawl Budgets — denn das kannst du selbst nicht verändern und damit auch nicht optimieren.
Die Crawl Budget-Optimierung beschäftigt sich damit, die Crawls der Suchmaschinen-Spider möglichst effektiv auszunutzen. Es geht also darum, die Crawls deiner Website so zu steuern, dass kein Crawl Budget an Inhalte verschwendet wird, das entweder gar nicht erst indexiert werden muss bzw. soll (noindex-Tag) oder nur sehr selten geändert werden.
Frage dich immer: Macht das Crawling für diesen Inhalt Sinn?
Hier einige Beispiele, die nicht in den Index sollen/müssen:
- Das Backend deines CMS
- Wunschlisten eines Online-Shops
- Recommend-Listen eines Online-Shops
- Print-Exemplare, z.B. von Rezepten
- noindex-Seiten
- Seiten mit einem Statuscode, der NICHT 200 ist (301, 404, 503 etc.)
7 Maßnahmen, die dir beim idealen Ausnutzen deines Crawl Budgets helfen
1. robots.txt richtig einsetzen
 Die robots.txt ist ein mächtiges Hilfsmittel, um unnötig aufgewendetes Crawl Budget einzusparen und Kapazitäten für relevante Crawls freizumachen.
Die robots.txt ist ein mächtiges Hilfsmittel, um unnötig aufgewendetes Crawl Budget einzusparen und Kapazitäten für relevante Crawls freizumachen.
Die robots.txt steuert das Verhalten der Crawler auf deiner Website. Sie definiert, welche Seiten, Verzeichnisse oder Bereiche für Crawler gesperrt sind und welche sie besuchen dürfen.
Überprüfe, welche Inhalte deiner Website aktuell für das Crawling freigegeben sind und ob eine Aufnahme in den Suchmaschinenindex überhaupt sinnvoll ist. Dabei entdeckst du möglicherweise Seiten, die unnötig gecrawlt werden und so wertvolles Crawl Budget verschwenden.
![]()
![]() Seiten, die nicht gecrawlt werden dürfen, werden in den meisten Fällen auch nicht indexiert. So kannst du mit einem Befehl ganze Verzeichnisse, Pfade und mehr aus dem Index halten, ohne dafür ggf. hunderte URLs händisch mit den noindex-Tag versehen zu müssen. Hinzu kommt, dass mit einem noindex-Tag versehene Seiten unnötig gecrawlt werden und so Crawl Budget verschwenden.
Seiten, die nicht gecrawlt werden dürfen, werden in den meisten Fällen auch nicht indexiert. So kannst du mit einem Befehl ganze Verzeichnisse, Pfade und mehr aus dem Index halten, ohne dafür ggf. hunderte URLs händisch mit den noindex-Tag versehen zu müssen. Hinzu kommt, dass mit einem noindex-Tag versehene Seiten unnötig gecrawlt werden und so Crawl Budget verschwenden.
![]()
![]() Was die robots.txt alles kann, wie du richtig mit ihr umgehst und worauf du achten musst, erfährst du hier.
Was die robots.txt alles kann, wie du richtig mit ihr umgehst und worauf du achten musst, erfährst du hier.
2. Sitemap in der GSC hochladen
 Die XML-Sitemap ist wie eine Landkarte oder ein Inhaltsverzeichnis deiner Website. Suchmaschinen-Crawler nutzen sie, um sich schnell ein Bild deiner Website zu verschaffen und deine Website effektiver crawlen zu können. Das gilt für jede Website, ist aber besonders für große, sehr verschachtelte Websites oder solche mit einem großen Archiv unverzichtbar.
Die XML-Sitemap ist wie eine Landkarte oder ein Inhaltsverzeichnis deiner Website. Suchmaschinen-Crawler nutzen sie, um sich schnell ein Bild deiner Website zu verschaffen und deine Website effektiver crawlen zu können. Das gilt für jede Website, ist aber besonders für große, sehr verschachtelte Websites oder solche mit einem großen Archiv unverzichtbar.
Die Sitemap bildet die Struktur (und damit die Schwerpunkte) deiner Website ab und enthält alle Unterseiten. Darüber können Metadaten enthalten sein, die Informationen über Aktualisierungen und Änderungen an einzelnen Seiten sowie über die Bedeutung / Beziehung der einzelnen Seiten zueinander.
Die XML Sitemap wird im Root-Verzeichnis deiner Website (erreichbar unter website.de/sitemap.xml) sowie in der Google Search Console hochgeladen.
![]()
![]() Natürlich haben wir für dich einen umfangreichen Artikel über die Notwendigkeit, das Erstellen und das Hochladen der Sitemap in die Google Search Console erstellt. Hier erfährst du alles, was du für eine erfolgreiche Umsetzung wissen musst.
Natürlich haben wir für dich einen umfangreichen Artikel über die Notwendigkeit, das Erstellen und das Hochladen der Sitemap in die Google Search Console erstellt. Hier erfährst du alles, was du für eine erfolgreiche Umsetzung wissen musst.
3. Crawlen von URLs mit Parametern verhindern
 URL-Parameter kommen auf fast jeder Website zum Einsatz. Zum Beispiel, um Traffic zu tracken oder beim Einsatz von Filtern und Sortier-Funktionen in Online-Shops. Diese URLs produzieren Duplicate Content und haben im Suchmaschinenindex nichts verloren. Werden sie gecrawlt, wird Crawl Budget verschwendet.
URL-Parameter kommen auf fast jeder Website zum Einsatz. Zum Beispiel, um Traffic zu tracken oder beim Einsatz von Filtern und Sortier-Funktionen in Online-Shops. Diese URLs produzieren Duplicate Content und haben im Suchmaschinenindex nichts verloren. Werden sie gecrawlt, wird Crawl Budget verschwendet.
Überprüfe,
- welche Parameter (z.B. “?s=seo” für eine Suchfunktion) auf deiner Website zum Einsatz kommen und
- ob sie noch relevant sind oder entfernt werden sollten
- ob eine andere Lösung infrage kommt (z.B. Cookies)
In der Regel ist Google in der Lage, parametrierte URLs zu erkennen und als solche zu behandeln. Dennoch kann es vorkommen, dass diese URLs gecrawlt werden und unnötig Crawl Budget verschwenden.
Aktuell (Stand März 2020) kannst du das Crawling von parametrierten URLs in der alten Google Search Console ausschließen. Ob diese Funktion bald abgeschaltet wird oder in die neue GSC überführt wird, bleibt abzuwarten.
Die Voraussetzungen dafür sind:
- Deine Website umfasst mehr als 1000 URLs
- Deine Protokolle zeigen einen hohen Anteil von indexierten, mit URL-Parametern duplizierten Seiten, die sich inhaltlich nur gering voneinander unterscheiden
 Der Ausschluß des Crawlings von parametrierten URLs kann schnell zu unbeabsichtigten Effekten im Crawling führen und sollte nur von erfahrenen SEO-Profis durchgeführt werden. Achte genau darauf, dass du die obigen Anforderungen erfüllst.
Der Ausschluß des Crawlings von parametrierten URLs kann schnell zu unbeabsichtigten Effekten im Crawling führen und sollte nur von erfahrenen SEO-Profis durchgeführt werden. Achte genau darauf, dass du die obigen Anforderungen erfüllst.
Im URL-Parameter Tool der Google Search Console kannst du nun festlegen, dass URLs mit einem bestimmten Parameter nicht mehr gecrawlt werden sollen. Bedenke dabei, dass diese Regel für die gesamte Property gilt und nicht exklusiv auf einzelne URLs oder Bereiche deiner Website angewendet werden kann.
Einen ausführlichen Artikel über SEO und URL Parameter findest du beim Search Engine Journal.
4. Interne Verlinkung optimieren
 Eine Website mit einer guten internen Verlinkung macht es den Crawlern einfach, deine Website zu navigieren und ihre Struktur, Zusammenhänge und wichtigsten Landing Pages zu identifizieren.
Eine Website mit einer guten internen Verlinkung macht es den Crawlern einfach, deine Website zu navigieren und ihre Struktur, Zusammenhänge und wichtigsten Landing Pages zu identifizieren.
Denn: Viel verlinkte Seiten deuten darauf hin, dass es sich um eine für deine Website verhältnismäßig wichtige Seite handelt.
Du ermöglichst den Crawlern, jede für die SERPs relevante Seite über interne Links zu erreichen. Das reduziert die Zahl sogenannter Orphan Pages – also Unterseiten, die wegen mangelnder externer und interner Verlinkung nicht oder nur schwer von Crawlern erreicht werden können.
![]()
![]() Schludere also nicht bei der internen Verlinkung. Selbstverständlich haben wir für dich eine umfangreiche Anleitung, wie du deine interne Verlinkung optimierst.
Schludere also nicht bei der internen Verlinkung. Selbstverständlich haben wir für dich eine umfangreiche Anleitung, wie du deine interne Verlinkung optimierst.
5. Statuscodes korrigieren
 Jede Weiterleitung, jede 404-Seite verbraucht unnötiges Crawl Budget. Ganz abgesehen davon, dass Error-Pages die User Experience stark in Mitleidenschaft ziehen, sind es auch unnötig gecrawlte Seiten.
Jede Weiterleitung, jede 404-Seite verbraucht unnötiges Crawl Budget. Ganz abgesehen davon, dass Error-Pages die User Experience stark in Mitleidenschaft ziehen, sind es auch unnötig gecrawlte Seiten.
Klar, Weiterleitungen sind ganz normal und lassen sich nicht vermeiden. Achte aber darauf, dass du sie auf einem Minimum hältst und dass keine Weiterleitungsketten entstehen. Sie erzeugen einen unnötig langen Weg für den Crawler, um an das letztliche Linkziel zu kommen und können ab 3 Sprüngen zu einem echten Problem für den Google Bot werden. Tu dir also selbst den gefallen und verhindere Weiterleitungsketten.
Wenn du einen Inhalt von deiner Seite entfernst, nutze ein SEO Tool, um interne Links zu identifizieren, die auf diese Seite zeigen und passe diese internen Links direkt an das neue Linkziel an. Richte dann die Weiterleitung auf das neue Ziel ein und entferne die Seite.
Grundsätzlich solltest du sicherstellen, dass der Großteil deiner URLs den Statuscode 200=OK aufweist. Dann ist alles in Ordnung. 404 Seiten sind Sackgassen für den Crawler und den Nutzer. Überprüfe deine Seite regelmäßig auf 404 Fehler und behebe sie schnellstmöglich. Weiterleitungen (301-Redirects) sind, reflektiert sowie Nutzer- und Crawler-freundlich eingesetzt, auch kein Problem. Um alles andere solltest du dich zeitnah kümmern.
![]()
![]() Hier findest du eine Übersicht über alle für SEO relevanten Statuscodes, was sie bedeuten und wie du sie behebst.
Hier findest du eine Übersicht über alle für SEO relevanten Statuscodes, was sie bedeuten und wie du sie behebst.
6. Pagespeed optimieren
 Die Erhöhung deiner Ladezeit ist eine weitere Möglichkeit, dein Crawl Budget zu optimieren. Eine hohe Ladezeit bedeutet immer auch große Datenmengen. Genau diese Datenmengen fressen nicht nur die Geduld deiner Nutzer, sondern auch dein Crawl Budget. Denn wie bereits erwähnt, ist das Crawl Budget ein Zeitbudget. Müssen die Crawler pro Seite große Datenmengen verarbeiten, schmälert das die Anzahl der im Zeitfenster crawlbaren Seiten.
Die Erhöhung deiner Ladezeit ist eine weitere Möglichkeit, dein Crawl Budget zu optimieren. Eine hohe Ladezeit bedeutet immer auch große Datenmengen. Genau diese Datenmengen fressen nicht nur die Geduld deiner Nutzer, sondern auch dein Crawl Budget. Denn wie bereits erwähnt, ist das Crawl Budget ein Zeitbudget. Müssen die Crawler pro Seite große Datenmengen verarbeiten, schmälert das die Anzahl der im Zeitfenster crawlbaren Seiten.
Eine schnell ladende Website ist also nicht nur für die User Experience und deine Rankings gut, sondern erhöht aufgrund der niedrigeren Datenmenge auch die Crawls, die für Datenvolumen X durchgeführt werden können.
![]()
![]() Hier findest du einen umfassenden Artikel über Möglichkeiten, wie du deine Ladezeit verbessern kannst.
Hier findest du einen umfassenden Artikel über Möglichkeiten, wie du deine Ladezeit verbessern kannst.
7. Den Canonical Tag richtig einsetzen
…und Duplicate Content verhindern.
 Der Canonical Tag wird genutzt, um das ‘Original’ von identischen oder sehr ähnlichen Inhalten zu markieren. Zum Beispiel, wenn durch den Einsatz von URL-Parametern Duplikate entstehen. Was URL Parameter sind, haben wir bereits weiter oben besprochen. Duplicate Content ist von den Suchmaschinen nicht gern gesehen und verschwendet dein Crawl Budget.
Der Canonical Tag wird genutzt, um das ‘Original’ von identischen oder sehr ähnlichen Inhalten zu markieren. Zum Beispiel, wenn durch den Einsatz von URL-Parametern Duplikate entstehen. Was URL Parameter sind, haben wir bereits weiter oben besprochen. Duplicate Content ist von den Suchmaschinen nicht gern gesehen und verschwendet dein Crawl Budget.
Der Canonical Tag zeigt der Suchmaschine also, dass es sich hier um einen Zwilling handelt, der nicht extra indexiert werden muss.
![]()
![]() Wie du den Canonical Tag richtig einsetzt und worauf du achten musst, erfährst du hier.
Wie du den Canonical Tag richtig einsetzt und worauf du achten musst, erfährst du hier.
Deine Checkliste für die Crawl Budget Optimierung
Natürlich haben wir für dich alle 7 Maßnahmen für die Crawl Budget Optimierung in einer praktischen Checkliste zusammengestellt. Du kannst sie dir ganz einfach als PDF herunterladen und hast sie immer griffbereit.

Wir hoffen, du hast viel über das Crawl Budget gelernt und kannst jetzt erkennen, ob du eine Crawl Budget-Optimierung durchführen solltest und welche Maßnahmen du dafür ergreifen musst.