Wie erstelle ich die robots.txt?


- Was ist die robots.txt?
- Ist die robots.txt Pflicht?
- Welche Vorteile hat die robots.txt?
- Welche Nachteile hat die robots.txt?
- Wo finde ich die robots.txt?
- Wie ist die robots.txt aufgebaut?
- Welche Eingaben gibt es?
- Welche Pfade/Verzeichnisse werden häufig ausgeschlossen?
- Was sind häufige Fehler und wie vermeide ich sie?
- Welche Befehle gehören NICHT in die robots.txt?
- Sitemap in robots.txt - ja oder nein?
- Was ist der Unterschied zwischen der robots.txt und noindex?
- Robots.txt mit der Google Search Console testen
- So interagieren die robots.txt und der Crawler
- Das disallow-noindex-Dilemma
- 'noindex' in der robots.txt
- Indexierung trotz Disallow:-Blockierung?
- Was sind die bekanntesten Crawler?
Wenn du eine Website betreust solltest du wissen, was eine robots.txt ist, warum sie wichtig ist, wie sie aufgebaut ist und wie man mit ihr richtig umgeht. Denn 2019 standen größere Änderungen ins Haus, die für viele die Überarbeitung der robots.txt notwendig machten. Deswegen haben wir für dich eine Übersicht zusammengestellt, die dir die wichtigsten Merkmale leicht verständlich näher bringen. Danach solltest du grundlegend in der Lage sein, dich mit der robots.txt deiner Website auseinanderzusetzen.
Was ist die robots.txt?
Die robots.txt ist quasi das Regelbuch deiner Website für Crawler. Sie wird auch Robots Exclusion Standard bzw. Robots Exclusion Protocol bezeichnet und liegt im Root-Verzeichnis der Website. Dabei handelt es sich um eine Textdatei (daher das Dateiformat .txt) die vorgibt, welche Crawler welche Bereiche deiner Website crawlen dürfen, und welche nicht. Daher ist die robots.txt auch die erste Anlaufstelle für Bots, die zu deiner Seite kommen. Du kannst sie auch als Türsteher betrachten.
Mit der robots.txt definierst du den Crawler-Zugriff auf 
- Verzeichnisse
- Pfade
- Dateiformate
- Dateien
- URL-Parameter
- Sitemaps
Seit ihrer Erfindung 1994 erfreute sich die robots.txt größter Beliebtheit, wurde aber nie offiziell als Internet Standard anerkannt. Damit wuchsen die Interpretation des Dokuments (durch Developer und Crawler) sowie die verwendeten Regeln, sodass mitunter Unsicherheit über die richtige Formulierung der Directives entstand. Das will Google seit dem 01. Juli 2019 ändern und die robots.txt zum Internet Standard machen.
Ist die robots.txt Pflicht?
 Nein. Die robots.txt ist kein Muss, wird aber unbedingt empfohlen. Schließlich steuert die robots.txt das Crawler-Verhalten auf deiner Website. Existiert sie nicht, können die Bots ungehindert deine Inhalte erfassen. Oder die Suchmaschinen machen auf der Stelle kehrt und crawlen deine Seite gar nicht. Deine gesamte Website zu crawlen, würde schließlich eine ganze Menge Crawl-Budget kosten.
Nein. Die robots.txt ist kein Muss, wird aber unbedingt empfohlen. Schließlich steuert die robots.txt das Crawler-Verhalten auf deiner Website. Existiert sie nicht, können die Bots ungehindert deine Inhalte erfassen. Oder die Suchmaschinen machen auf der Stelle kehrt und crawlen deine Seite gar nicht. Deine gesamte Website zu crawlen, würde schließlich eine ganze Menge Crawl-Budget kosten.
Welche Vorteile hat die robots.txt?
- Du kannst das Verhalten von Suchmaschinen auf deiner Website beeinflussen. Das ist auch über Meta Tags möglich, ist aber aufwendiger und nur für die HTML-Datei möglich, nicht aber für darin enthaltene Dateien wie Bilder.
- Du kannst Crawl-Budget einsparen. Du hast eine große Website mit tausenden Unterseiten, die für Suchmaschinen-Traffic ungeeignet sind? Dann erspare den Crawlern den unnützen Weg über diese Seiten.
- Du kannst das Website-Management von Verzeichnissen und Dokumenten vereinfachen. Klar kannst du für Suchmaschinen irrelevante Seiten mit dem ’noindex‘-Tag von den SERPs ausschließen. Dieser muss aber für jede URL einzeln gesetzt werden – was bei hunderten oder tausenden Seiten aufwendig und unübersichtlich ist. Da ist es viel einfacher, diese Verzeichnisse oder Dokumente in der robots.txt per Disallow auszuschließen.
Welche Nachteile hat die robots.txt?
- Die robots.txt gibt den Crawlern lediglich Richtlinien vor, ihr Wort ist aber nicht Gesetz. Das bedeutet: es liegt im Ermessen der Crawler bzw. Suchmaschinen, ob sie deinen Anweisungen Folge leisten, oder auch nicht. Die meisten Suchmaschinen halten sich in der Regel an die robots.txt. Crawler mit bösen Absichten sind nicht an Weisungen der robots.txt gebunden und ignorieren sie.
- Seiten, die unter die Disallow-Directive fallen, können keinen Linkjuice weitergeben. Aus SEO-Perspektive werden sie damit nutzlos.
- Disallow-Seiten, die Backlinks erhalten, werden indexiert und erhalten den Ankertext der Link-gebenden Seite als Snippet. Sie tauchen also trotz disallow im Index auf.
Wo finde ich die robots.txt?
Die robots.txt befindet sich im Root-Verzeichnis deiner Website. Wenn du eine WordPress-Website hast, befinden sich in diesem Ordner auch die .htaccess-Datei und die wp-config.php. Es kann immer nur eine robots.txt pro Domain geben. Subdomains erhalten jeweils ein eigenes Dokument.
Wie ist die robots.txt aufgebaut?
Die Syntax (Aufbau) der robots.txt folgt immer demselben Muster. Sie besteht aus mindestens einer Gruppe mit Regeln, die sich an alle Webcrawler richten. Die Gruppe beginnt immer mit dem Adressaten, der auch User-agent genannt wird und festlegt, an welche Webcrawler sich die folgenden Regeln richten. Darauf folgen Directives (Regeln) und falls gewünscht, nicht Crawler-spezifische Hinweise (z.B. Angabe der Sitemap) oder Kommentare.
| Anfang der Gruppe |
User-agent: |
| Datensatz für Gruppenmitglieder |
Disallow: |
| Datensatz für Gruppenmitglieder |
Allow: |
| Nicht gruppenspezifische Angaben |
Sitemap: |
In der Praxis kann eine einfache robots.txt so aussehen:
User-agent: * Disallow: /verzeichnis/ Allow: /verzeichnis/unterseite Sitemap: https://www.deinedomain.de/sitemap.xml
Spezifikationen für bestimmte Crawler werden (durch eine Leerzeile getrennt) in jeweils weiteren Gruppen angegeben. Der, bzw. die User-agent(s), für die ein Set an Regeln gilt, wird immer in einer eigenen Gruppe angegeben. Die robots.txt wird von den Bots immer von oben nach unten gelesen. Findet beispielsweise der Googlebot explizit an ihn gerichtete Directives, hält er sich an diese und ignoriert er alle anderen. Daher ist es sinnvoll, erst die Regeln für spezifische Crawler abzuhandeln und danach auf die allgemein gültigen Regeln einzugehen. Das sieht kann dann so aussehen:
User-agent: Googlebot User-agent: Bingbot Disallow: /verzeichnis1/ Allow: /verzeichnis/unterseite-b User-agent: * Disallow: /verzeichnis2/ Allow: /verzeichnis/unterseite-d
Welche Eingaben gibt es?
| Eingabe | Art | Funktion | Beispiel |
|---|---|---|---|
| User-agent: | Ansprache Crawler | Legt fest, für welchen Bot die folgenden Regeln gelten |
User-agent: Googlebot |
| Disallow: | Regel | Verbietet das Crawlen der Verzeichnisse / Dateien |
Disallow: /verzeichnisx/ |
| Allow: | Ausnahme zur vorausgehenden Regel | Erlaubt das Crawlen der Verzeichnisse / Dateien |
Allow: /verzeichnisx/das-ist-gut |
| Sitemap: | Hinweis | Zeigt die Adresse der Sitemap |
Sitemap: https://www.domain.de/sitemap.xml |
| * | Platzhalter | Wildcard. “Gilt für alle”-Definition |
User-agent: * |
| $ | Platzhalter | Kennzeichnet das Ende der URL |
Allow: .png$ |
| # | Hinweis | Markiert eine Kommentarzeile |
#robots.txt von Arno Nym |
Auf diese Formatierung solltest du achten:
- Richtige Gruppen-Reihenfolge: Setze Crawler-spezifische Regeln zuerst, dann erst die allgemeingültige Gruppe.
- Groß-/Kleinschreibung: Dateiname MUSS robots.txt sein. Achte auf die richtige Schreibweise von Pfaden und Verzeichnissen.
- Zeichensetzung: Denk an den Doppelpunkt (.) bzw. Slash (/)!
- Ein Directive/User-agent pro Zeile. Widme jeder Regel und jedem User-Agent eine eigene Zeile. Wenn du zwei Verzeichnisse sperren möchtest, bekommt jedes Verzeichnis ein Disallow-Directive in einer eigenen Zeile.
Ausführliche Beispiele für den korrekten und falschen Umgang mit den verschiedenen Directives findest du bei den Spezifikationen von Google.
Allow und Disallow
Im Prinzip gibt es „nur“ zwei Typen von Anweisungen, nämlich „Allow“ und „Disallow“. Übersetzt bedeutet das „Erlauben“ und „Nicht erlauben“. Damit erklärt es sich fast von selbst. Grundsätzlich sind erstmal alle Dateien zum Crawling freigegeben. Es ist also nicht nötig, alle erlaubten Inhalte mit allow auszuzeichnen.
Möchte man nun einzelne Verzeichnisse oder URLs vom Crawling ausschließen, so stellt man „Disallow“ voran und benennt dann das Verzeichnis. Eine relative Adressierung reicht danach aus.
Beispiel
Disallow: /admin
Damit wird das Admin-Verzeichnis einer Webinstallation vom Crawling ausgeschlossen. So einfach wird der Befehl ausgeführt. Gibt es weitere Verzeichnisse, die für Bots gesperrt werden sollen, so kann man dort einfach weitere Zeilen darunter schreiben.
Disallow: /wp-admin/ Disallow: /xmlrpc.php
So kann man das im Prinzip unendlich fortführen.
Mit dem Allow-Befehl wird genau das Gegenteil bewirkt. Gibt es z. B. ein Verzeichnis, welches grundsätzlich nicht gecrawlt werden soll, dann kann es innerhalb dieses Verzeichnisses vielleicht eine URL geben, die trotzdem frei gegeben werden soll. Die Ausnahme zur Regel also. Hier kannst du dann eine neue Zeile erstellen, die mit „Allow:“ beginnt. Dies ist vor allem im Zusammenhang mit Disallow-Anweisungen nützlich, durch die große Teile einer Site mit Disallow gesperrt sind außer eines kleinen Teils, der darin eingeschlossen ist.
Wildcard-Anweisungen
Durch den Einsatz von Wildcards, kann man auch bestimmte Arten von URLs vom Crawling ausschließen.
| Beispiele für Wildcards | |
| Ausschluss aller gif-Dateien: |
Disallow: /*.gif$ |
| Blockieren von URLs, die Fragezeichen (?) enthalten |
Disallow: /*? |
| Blockieren einer beliebigen Zeichenfolge mit * |
Disallow: /private*/ |
Kommentare
Um die Übersicht zu behalten, können Kommentarzeilen hilfreich sein. Jede Kommentarzeile beginnt mit einem Hashtag (#). Das ist das Zeichen für den Crawler, dass er die Inhalte dieser Zeile nicht berücksichtigen muss. Hashtags können an jeder Stelle in der robots.txt eingefügt werden. Oft findet man sie am Anfang der robots.txt oder über bzw. unter einzelnen Gruppen.
# Regel für alle Crawler User-agent: * Disallow: /verzeichnis/ Allow: /verzeichnis/unterseite Sitemap: https://www.deinedomain.de/sitemap.xml
Welche Verzeichnisse und Pfade werden häufig ausgeschlossen?
Webmaster schließen häufig ihr Backend und ihren Login-Bereich vom Crawling aus. Wenn du eine WordPress-Seite betreibst, könnte eine entsprechende robots.txt so aussehen:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Disallow: /wp-login.php
Was sind häufige Fehler und wie vermeide ich sie?
- Falsche Dokument-Bezeichnung. Die robots.txt MUSS komplett kleingeschrieben werden. Crawler arbeiten case-sensitive; Robots.txt und robots.txt sind für sie zwei Paar Schuhe.


- Falsche Speicherung. Die robots.txt muss im Root-verzeichnis deiner Website liegen. Wenn du eine WordPress-Website hast, befinden sich in diesem Ordner auch die .htaccess-Datei und die wp-config.php.
- Fehlende Anweisungen.
- Schreibweise. Achte auf eine korrekte Schreibweise der Directives, User-agents, Verzeichnisse und Dokumenten.
- JavaScript wird blockiert. Achte darauf, dass admin-ajax.php nicht blockiert wird.
- Disallow: / statt Disallow: Ein Slash zuviel kann deine gesamte Website blockieren. Disallow: / schließt alle Pfade und Verzeichnisse vom Crawling aus. Disallow: schließt nichts vom Crawling aus.
Welche Befehle gehören NICHT in die robots.txt?
Ab dem 01. September 2019 werden die bisher akzeptierten, aber dennoch inoffiziellen Regeln der robots.txt von Google nicht mehr unterstützt. Das bedeutet, dass die Googlebots diesen Directives nicht mehr folgen werden. Dazu zählen:
- noindex
- nofollow
- crawl-delay
‘noindex’ und ‘nofollow’ sind Meta-Tags. Setze sie entsprechend ein. Darüber hinaus findest du hier ein paar Alternativen zu ‘noindex’ in der robots.txt.
Was ist der Unterschied zwischen der robots.txt und ’noindex‘?
Häufig werden die Aufgaben der robots.txt und die der Meta-Tags miteinander verwechselt. Die robots.txt ist eine Textdatei und steuert das Crawling deiner Website durch Crawler wie den Googlebot. Sie legt fest, welche Seiten welcher Bot “betreten” darf.
‘noindex’ ist ein Meta-Tag wird in den HTML Code bzw. den HTTP-Antwort-Header einer Seite eingebettet. ‘noindex’ verbietet nicht das Crawling durch den Bot, sondern die Aufnahme der URL in den Index der Suchmaschine.
| robots.txt | Crawling | “Du kommst hier (nicht) rein” |
| Meta-Tags | Indexierung | “Das soll (nicht) in die SERPs” |
Robots.txt mit der Google Search Console testen
In der Google Search Console Hilfe gelangst du zum robots.txt Tester, der einst in der Search Console zu finden war. Hier kannst du deine robots.txt auf Fehler untersuchen.
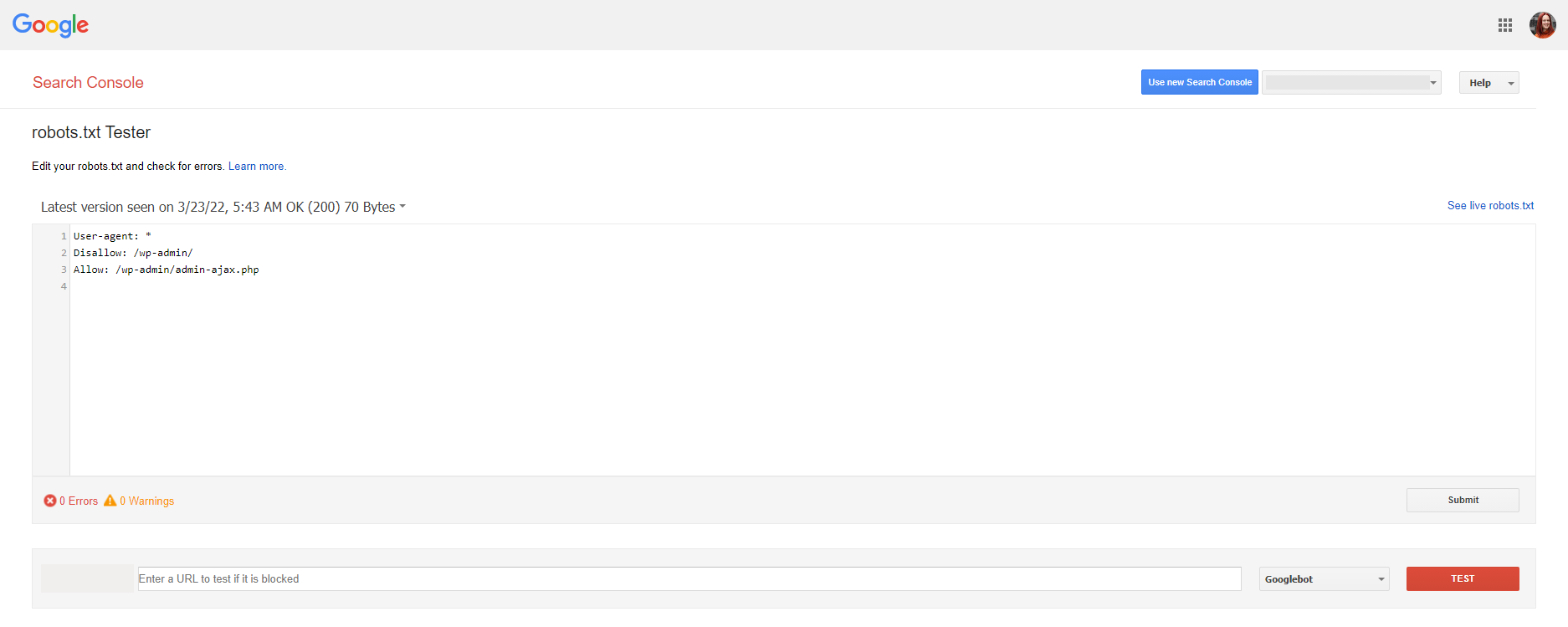
Du findest den Tester über das Menü unter dem Punkt „Crawling“ und “robots.txt-Tester”. Da deine Domain ja schon hinterlegt ist, kannst du dort direkt die robots.txt anschauen. Darunter findest du dann die Hinweise auf etwaige Fehler und Warnmeldungen. In unserem Beispiel finden sich keine Fehler oder Warnungen. Hier ist alles in Ordnung.
Im Screenshot siehst du dir robots.txt einer WordPress-Installation, in der der Admin-Bereich ausgeschlossen wird. Über den Befehl „Allow:“ wird das JavaScript zum Crawling freigegeben.
So testest du die robots.txt-Datei im Google-Tool:
Öffne den Tester für deine Website. Scrolle durch den Code der robots.txt-Datei, um die hervorgehobenen Syntaxwarnungen und logischen Fehler zu ermitteln. Unterhalb des Editors siehst du die Anzahl an Syntaxwarnungen und logischen Fehlern in deiner Datei.
- In der Eingabemaske gibst du die URL deiner Website ein.
- Im Drop-Down rechts neben dem Textfeld wählst du den User-Agent aus, der simuliert werden soll.
- Klicke auf die Schaltfläche “Testen”, um den Test zu starten.
- Überprüfe, ob die eingegebene URL für die Web-Crawler von Google blockiert ist. Du bekommst die Meldung “Zulässig” oder “Blockiert”.
- Bearbeite die Datei und führe den Test gegebenenfalls erneut durch. Hinweis: Änderungen an der robots.txt, die du im Test-Tool vornimmst, werden nicht auf deiner Website gespeichert. Fahre mit dem nächsten Schritt fort.
- Füge die Änderungen in die robots.txt-Datei auf deiner Website ein.
So interagieren die robots.txt und der Crawler auf deiner Domain
Wenn alles glatt läuft, können die robots.txt und der Crawler hervorragend miteinander kommunizieren. Doch es gibt Momente im Leben der zwei, wenn Konflikte sprichwörtlich vorprogrammiert sind. Wir haben dir hier eine kleine Infografik zusammengestellt, die das Zusammenspiel veranschaulicht. Weiter unten findest du zusätzlich drei Fälle, in denen die zwei sich nicht so gut verstehen.
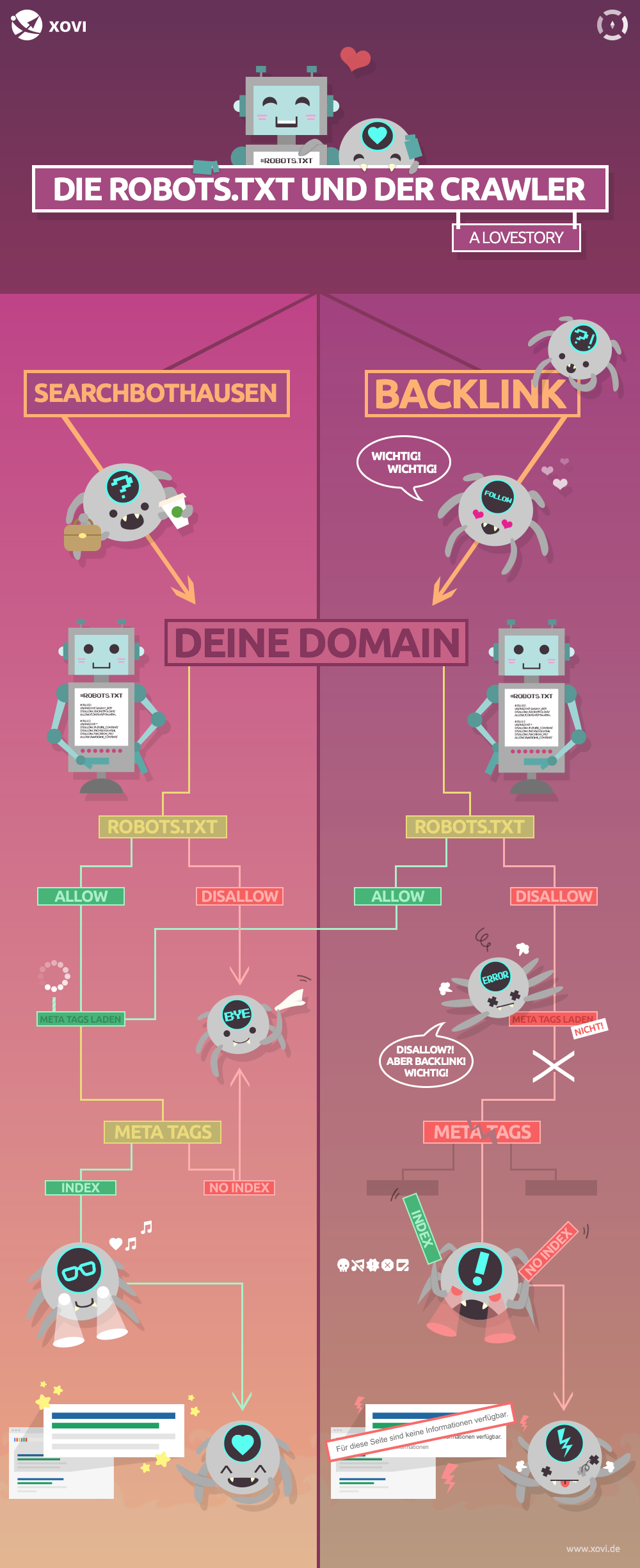
Das Disallow-noindex-Dilemma
Meine Seite hat ein ’noindex‘, ist aber trotzdem in den Suchergebnissen. Wie kann das sein?
 Das Phänomen tritt recht häufig auf, wenn die Seite bereits im Index war, bevor man diese ausgeschlossen hat. Wenn eine Seite durch robots.txt blockiert ist, sieht der Crawler einen ggf. gesetzten ‘noindex’-Tag nicht. Der befindet sich schließlich auf der Seite, die der Crawler nicht betreten soll. Die Seite kann dann trotzdem in den Suchergebnissen erscheinen (z.B. durch frühere Indexierung, interne Verlinkung oder Backlinks).
Das Phänomen tritt recht häufig auf, wenn die Seite bereits im Index war, bevor man diese ausgeschlossen hat. Wenn eine Seite durch robots.txt blockiert ist, sieht der Crawler einen ggf. gesetzten ‘noindex’-Tag nicht. Der befindet sich schließlich auf der Seite, die der Crawler nicht betreten soll. Die Seite kann dann trotzdem in den Suchergebnissen erscheinen (z.B. durch frühere Indexierung, interne Verlinkung oder Backlinks).
‘noindex’ in der robots.txt
Einige Webmaster nutzen ‘noindex’ auch in der robots.txt. Offiziell ist dies von Seiten Googles nicht so vorgesehen und wird ab dem 01. September 2019 auch nicht mehr unterstützt.
Today we’re saying goodbye to undocumented and unsupported rules in robots.txt 👋
If you were relying on these rules, learn about your options in our blog post.https://t.co/Go39kmFPLT
— Google Webmasters (@googlewmc) 2. Juli 2019
Tests in der Vergangenheit haben gezeigt, dass ein ‘noindex’ in der robots.txt bisher durchaus funktioniert hat – wenn auch nur sporadisch und nur, wenn das entsprechende Dokument das nächste mal gecrawlt wird. Eine zuverlässige Methode ist es jedenfalls nicht.
Das sieht Google genauso. Im Zuge der Standardisierung der robots.txt Datei hat das Google-Team die Verwendung von inoffiziellen robots.txt Regeln untersucht und folgendes festgestellt:
- Inoffizielle Directives werden recht selten eingesetzt
- In 99,999% aller Fälle widersprechen andere Regeln der inoffiziellen Directive
Solche Widersprüche können zu schwerwiegenden Crawling-Fehlern führen.
Indexierung trotz Disallow:-Blockierung?
Es kommt nicht selten vor, dass per Disallow gesperrte Inhalte trotzdem in Index landen. Dort erscheint dann ein Snippet mit der Description “Für diese Seite sind keine Informationen verfügbar”. Wie ist das passiert?
Klar, per Disallow blockierte Seiten werden nicht gecrawlt und landen dadurch auch nicht im Index. Stimmt’s? Jein. Wenn eine solche Seite über zahlreiche Backlinks verfügt, kommen die Crawler über den Backlink auf die URL. Google erachtet die URL aufgrund der Backlinks dann als so relevant, dass sie doch im Index landet. Für den Titel des Snippets wird dann der Ankertext herangezogen. Da der Crawler aber aufgrund der Disallow-Directive in der robots.txt die Seite nicht crawlt, können die Inhalte nicht im Snippet ausgegeben werden.
Wenn deine Domain solche Snippets produziert, hast du zwei Möglichkeiten:
- Du hebst die Disallow-Blockierung dieser URL auf, indem du per Allow: die URL von der Regel ausnimmst. Dann wird die Seite vollständig in den Index aufgenommen und du kannst die Metadaten für ein Snippet optimieren.
- Du hebst die Disallow-Blockierung dieser URL auf, indem du per Allow: die URL von der Regel ausnimmst. Dann versiehst du die Seite mit dem ’noindex‘-Tag um sicherzustellen, dass sie wirklich nicht in den SERPs auftaucht.
Was sind die bekanntesten Crawler?

Um deine robots.txt zu erstellen, musst du natürlich auch die wichtigsten Crawler kennen und adressieren können. Deswegen haben wir dir hier eine Liste der wichtigsten Crawler zusammengestellt.
| Crawler |
User-agent: |
|---|---|
| Googlebot für Computer |
Googlebot |
| Googlebot für Nachrichten |
Googlebot-News |
| Googlebot für Videos |
Googlebot-Video |
| Googlebot für Bilder |
Googlebot-Image |
| Googlebot für Desktop Google Ads |
AdsBot-Google |
| Googlebot für Mobile Ads |
AdsBot-Google-Mobile |
| Googlebot für Mediapartner |
Mediapartners-Google |
| Googlebot für APIs |
APIs-Google |
| Standard-Bingbot |
Bingbot |
| Ehemaliger Standard-Bingbot |
MSNBot |
| Bingbot für Bilder |
MSNBot-Media |
| Bingbot für Bing Ads |
AdldxBot |
| Bingbot für Page-Snapshots |
BingPreview |
| Yahoo Crawler / Slurp Bot |
Slurp |
| DuckDuckGo Bot |
DuckDuckBot |
| Baidu Spider (chinesische Suchmaschine) |
Baiduspider |
| Sogou Spider (chinesische Suchmaschine) |
Sogou web spider |
| Yandex Bot (russische Suchmaschine) |
YandexBot |
| Facebook (First time post) |
facebookexternalhit |
| Comscore Bot (Cross-plattform advertising) |
proximic |
| Exalead Bot (französische Suchmaschine) |
Exabot |
Hier findest du noch einige umfangreiche Listen mit Crawlern. Beachte bitte, dass einige dieser Listen schon mehrere Jahre alt sind und ggf. nicht mehr aktualisiert werden.
- Parse User Agents: Crawler User Agents (2019)
- Device Atlas: Most Active Bots and Crawlers on the Web (2019)
- User Agent String: List of all Crawlers (2018)
- Github: Crawler-User-Agents (2019)
- Network Lab: Information zu Bots, Spidern, Crawlern und Harvestern (2012)
Wir hoffen, dass wir deine Fragen zur robots.txt beantworten und dir alle Informationen an die Hand geben konnten, um die robots.txt zu verstehen. Beachte bitte, dass durch eigentsändige Änderungen an der robots.txt Fehler auftreten können, die dein Crawling und damit deine Rankings gefährden können. Verändere die robots.txt also nur, wenn die aktuelle Version fehlerhaft ist oder Änderungen dringend notwendig sind. Teste die robots.txt in jedem Fall mit dem Google Tester auf korrekte Ausführung, bevor du sie in deinem Root-verzeichnis abspeicherst.